Better together . —— Udacity
Hi,同学们,经过前两周的学习,我们掌握了描述统计学基础、概率论基础、推论统计学中的置信区间、假设检验以及机器学习入门知识——回归,本章的内容偏理论性更多一些,需要更多得去实操来加强自己的理解能力,这周呢我们就来个实打实的项目来检验前两周的所学。项目为分析A/B测试结果,在开始项目前,请一定要把前面的几个小测试做了,这样做项目更好上手一些。大家加油!通过这个项目,就可以拿到入门的毕业证啦!!!
项目四(P4)阶段总共包含三周,在这三周内,我们要对统计学进行学习,掌握基础的描述统计学理论、基本的概率知识、二项分布和贝叶斯公式,并学会使用 Python 来实践;学习正态分布、抽样分布、置信区间以及假设检验的概念和计算方式;学习线性回归以及逻辑回归,在真实场景中应用,比如分析 A/B 测试结果,搭建简单的监督机器学习模型。可谓是时间紧任务重,但是也别怕,统计学的基础知识还是非常简单的,跟着课程内容一步步来,自己多做笔记多查资料,一定没问题的!
那么我们的课程安排:
| 时间 | 学习重点 | 对应课程 |
|---|---|---|
| 第1周 | 统计学基础 | 描述统计学 - 抽样分布与中心极限定理 |
| 第2周 | 统计学进阶 | 置信区间 - 逻辑回归 |
| 第3周 | 完成项目 | 项目:分析A/B测试结果 |
本阶段可能是个挑战,请一定要保持自信,请一定要坚持学习和总结,如果遇到任何课程问题请参照如下顺序进行解决:
- 先自行查找问题答案(注意提取关键词),参考:谷歌/必应搜索、CSDN、stackoverflow
- 额外参考资料:
- 若问题未解决,请将问题及其所在课程章节发送至微信群,并@助教即可
饭要一口一口吃,路要一步一步走,大家不要被任务吓到,跟着导学一步一步来,肯定没问题哒!那我们开始吧!
注:本着按需知情原则,所涉及的知识点都是在数据分析过程中必须的、常用的,而不是最全面的,想要更丰富,那就需要你们课下再进一步的学习和探索!
本周目标
完成并通过项目四!
学习计划
| 时间 | 学习资源 | 学习内容 |
|---|---|---|
| 周二 | 微信群 - 每周导学 | 预览每周导学 |
| 周三、周四 | Udacity - Classroom | 项目四 |
| 周五 | 微信/Classin - 1V1 | 课程难点 |
| 周六 | Classin - 优达日 | 本周学习总结、答疑 |
| 周日 | 笔记本 | 总结沉淀 |
| 周一 | 自主学习 | 查漏补缺 |
项目指南
项目详情
数据分析师和数据学家经常使用 A/B 测试。在这个项目中,你将会理解电子商务网站运营 A/B 测试的结果。你的目标是通过课程中给的Jupyter Notebook,帮助公司理解他们是否应该设计新页面、保留原有网页或延长测试时间以便做出决定。
项目前面的几个小测试,需要大家针对项目提供的数据进行操作并回答,你可以打开两个网页,也可以在本地进行操作。
当然还是建议大家下载到本地进行操作,如果文件下载失败,请微信联系我。
关于A/B-test:
AB 测试就是为了验证在先验条件的存在的情况下,进行新的变更是否合理和可行以达到优化的目的。使用 AB 测试的方式能能够度量变更对某些指标的变化,是变更更具有合理性依据更充分。
AB 测试也存在 不适用的场景:1)对没有明确参照的试验,AB 测试是基于先验条件的优化,如果没有一个参照对比是无法进行测试。2)数据获取时间长,AB 测试一般都是进行小规模快速的试验,所以对于数据获取的单周期较长的试验不太适用。
影响测试效果的因素:1)新奇效应:即
Novelty Effect指老用户可能会觉得变化很新鲜,受变化吸引而偏爱新版本,哪怕从长远看来新版本并无益处。2)抗拒改变心理:即Change Aversion老用户可能会因为纯粹不喜欢改变而偏爱旧版本,哪怕从长远来看新版本更好。
在课程项目中,我们分成了三块涵盖了本章的所有知识点,这三块分别为:
- 概率
- A/B测试
- 回归
如果在项目进行中,有知识点遗漏或忘记的地方,可以去查看相关课程视频或者导学,之后,记在你的小本本上。
I - 概率
本节的问题都相对比较简单,所以在导学中不过多赘述了。
测试1-理解数据集
这里没什么难度,基本的pandas知识,如果这节有什么问题的话,请查看第六周导学并面壁十分钟-。-
如果非要提醒一下的话,那就是在问题e.
new_page与treatment不一致的次数中,不要忘了也看看old_page与control的不一致次数,二者相加才是结果。
测试3-更新后的数据集
- a问题中,因为要将处理后的数据集保存为新的变量,所以使用drop函数时,可以不用使用inplace = True参数。
- d问题中,因为两个重复值除了时间戳不一致外,其他信息都是一致的,所以随便删除一个重复即可。
II - A/B测试
1.零假设与备择假设
这里只说一点,就是如何在Jupyter Notebook中使用公式的问题,其实也就是如何在Markdown中使用公式的问题,你只需要按照如下步骤即可:
打开Latex公式在线转换,输入好公式后,复制代码
将你想要输入公式的代码框,转为Markdown格式;
输入两个美元符号,即$$;
将刚复制的公式代码粘贴到两个美元符号中间,然后运行该代码框即可。
录了一个gif在下面,可以参考下:
2.进行假设检验
- a、b
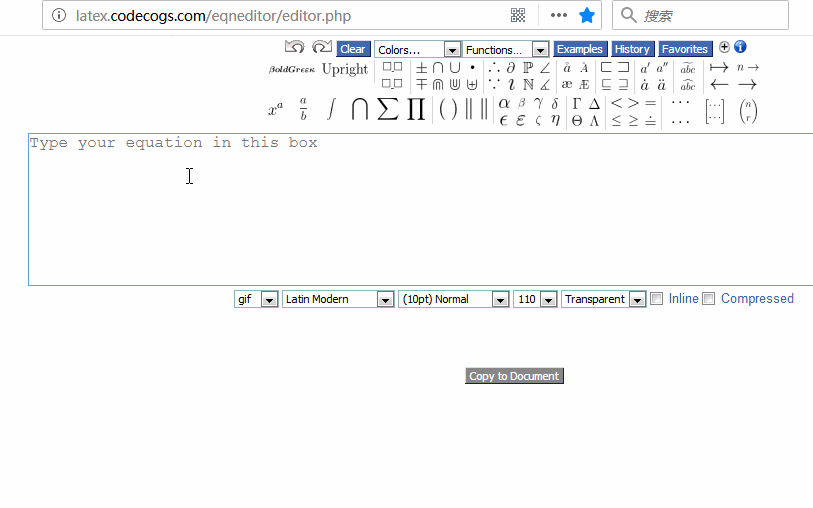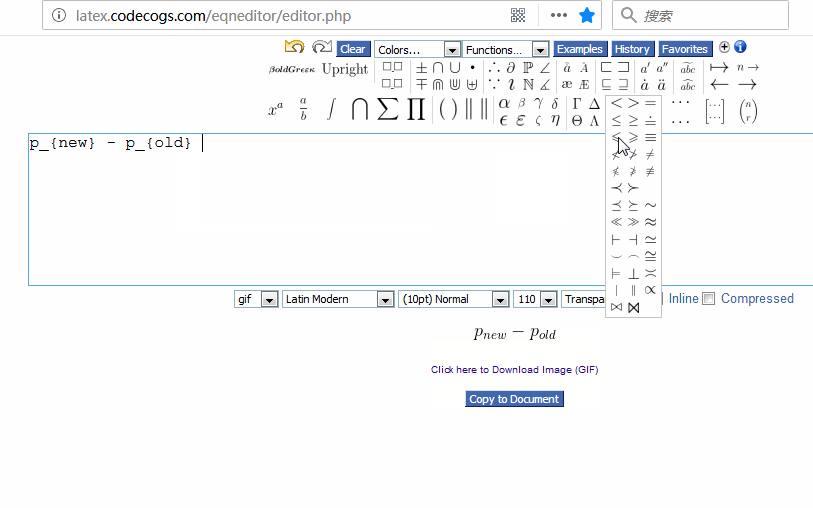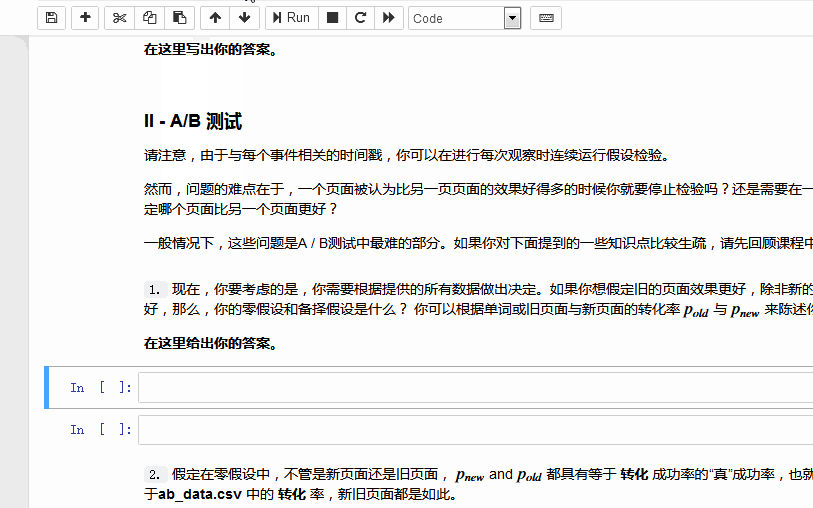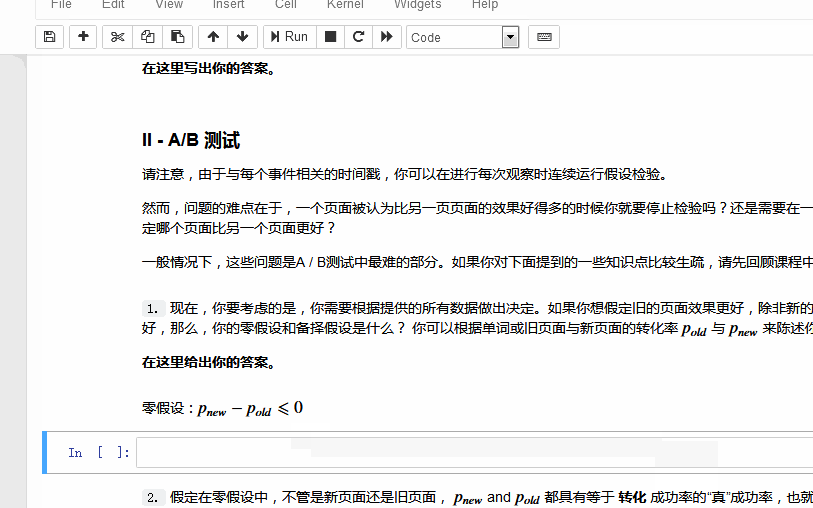
注意题干中给的要求是:假定在零假设中,不管是新页面还是旧页面, pnew 和 pold 都具有等于 转化 成功率的“真”成功率,也就是说, pnew 与 pold是相等的。此外,假设它们都等于ab_data.csv 中的 转化 率,新旧页面都是如此。
也就是:p_new = p_old = p_ab_data
注意:这并不意味着零假设就是p_new = p_old,可以从后续的c-g步骤能看出,零假设为p_new - p_old ≤ 0
- c、d
这里的n_new与n_old就是对ab_data中使用新旧页面的用户数量进行统计。
- e、f、g
使用numpy.random.choice函数,将零假设中的p_new与p_old作为抽样概率,n_new与n_old作为抽样次数,用1表示‘转化成功’,0表示‘未转化成功’,并将结果储存在一个新变量当中。
示例:
1 | new_page_converted = np.random.choice([0,1],n_new,p = [1-p_new,p_new]) |
以上获得的这个新变量,就是我们按照零假设中的n_new抽样n_new次的转化与否的分布模拟,那如何看模拟后的转化率呢?很简单,一个函数就搞定了,这里自己想。
- h、i、j
这三步是使用for循环,将上面的过程不断重复10000次,获得一个抽样分布直方图,这个图会是正态分布吗?
关于实际观测值,即为你利用ab_data.csv直接计算得来的new_page与old_page转化率之差。
j中得到的值是什么呢?是不是在零假设的条件下,观察到实际观测值甚至更极端(更支持备择假设)的概率?那这个值的学名叫什么?
【这里实际上进行的是单尾检验,也就是对备择假设为p_new - p_old > 0来进行的】
- i、m
使用了statsmodels中的proportions_ztest函数进行检验。实现的功能和上述a-j是一致的。
为什么要选择这个函数,以及这个函数的用法可以参考课程中给的链接proportions_ztest。
不过值得注意的是,在链接的列子中,使用的是双尾检验,也就是针对备择假设为p_new ≠ p_old去做的;但是在课程项目中,我们的备择假设为p_new > p_old,也就是单尾检验,所以函数中的某个参数要改一下。
使用内置函数方法获得的p值应该与前面获得的p值相近,如果差太多,那肯定是有地方需要再琢磨琢磨。
III - 回归
- a
要想知道执行哪种类型的回归,就应该先看变量是属于数值变量还是分类变量,那题设中的变量是什么类型的变量呢?
- b
要求是:创建一个 ab_page 列,当用户接收 treatment 时为1, control 时为0。所以在对group列使用get_dummies函数时,应该把生成的treatment列保存为ab_page列,而control列则应该被删掉。
- c、d
注意的一点是:不要忘了添加截距。在进行结果解释的时候,我们并不关注截距,只是关注变量的coef系数和p值,先看p值是否具有显著性,若有再看coef系数,若没有,则该变量对因变量没有影响。
- e
在思考零假设与备择假设之前,注意看结果中标红框的位置,想想这是什么意思,这说明在回归计算中,采用的是单尾检验还是双尾?单尾和双尾又分别对应的假设是什么?
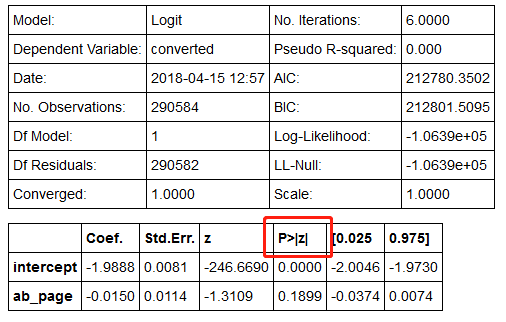
- g
数据集融合问题,之前单独出过一篇导学,如果忘了,请戳:Pandas数据融合,提醒下,合并时采用内连接,可以省去一些麻烦;
get_dummies,注意该函数生成数据的顺序是按照字典顺序来的,所以,你在进行操作时,为了确保顺序不乱,最好能先看一下生成的结果,再进行重命名。
总结
大家能坚持到最后一个项目,十分不易,不过对于数据分析生涯来说,这只是你的开始,请继续保持这段时间的学习状态,如果非要给这个保持加一个期限的话,我希望是一辈子!大家加油!等你们的好消息!!