Don’t let yesterday take up too much of today.
Hi,同学们,本周已经是P2阶段的第三周了,前两周我们学习了数据类型、控制流以及脚本编写等Python基础内容,还学习了Python做数据分析两个关键的第三方包——NumPy和Pandas,那么,接下来就到了检验学习、提高实战能力的时候了!
这周我们要挑战项目二:探索美国共享单车数据,争取能在本周完成项目并提交,加油!
| 时间 | 学习重点 | 对应课程 |
|---|---|---|
| 第1周 | Python基础内容 | 数据类型和运算符、控制流、函数、脚本编写 |
| 第2周 | Python数据处理内容 | Numpy & Pandas - 第一、二部分 |
| 第3周 | 完成项目 | 项目:探索美国共享单车数据 |
| 第4周 | 项目修改与通过 | 修改项目、查缺补漏、休息调整 |
对于非小白同学来说 ,本阶段内容不是很难,希望你们能在三周内完成并通过项目;
对于小白来说,本阶段可能是个挑战,请一定要保持自信,请一定要坚持学习和总结,如果遇到任何课程问题请参照如下顺序进行解决:
- 先自行查找问题答案(注意提取关键词),参考:谷歌/百度搜索、菜鸟教程、CSDN、stackoverflow、Python for Data Analysis, 2nd Edition 、Python Cookbook
- 若问题未解决,请将问题及其所在课程章节发送至微信群,并@助教即可
饭要一口一口吃,路要一步一步走,大家不要被任务吓到,跟着导学一步一步来,肯定没问题哒!那我们开始吧!
注:本着按需知情原则,所涉及的知识点都是在数据分析过程中必须的、常用的,而不是最全面的,想要更丰富,那就需要你们课下再进一步的学习和探索!
本周目标
- 完成并提交项目二。
学习计划
| 时间 | 学习资源 | 学习内容 |
|---|---|---|
| 周二 | 微信群 - 每周导学 | 预览每周导学 |
| 周三、周四 | Udacity - Classroom | 数据类型 - 脚本编写 |
| 周五 | 微信/Classin - 1V1 | 课程难点 |
| 周六 | Classin - 优达日 | 本周学习总结、答疑 |
| 周日 | 笔记本 | 总结沉淀 |
| 周一 | 自主学习 | 查漏补缺 |
项目准备
环境准备
强烈建议大家完成本地环境的搭建,在本地完成此项目。搭建本地环境的方法请参考Anaconda的安装与配置一节,完成后你将获得本项目中会用到的关键软件:Spyder和Jupyter Notebook。
文件准备
在此项目中,你将比较以下三座城市的共享单车使用情况:芝加哥、纽约市和华盛顿特区。这些数据由 Motivate 提供。
数据和项目文件下载,请参考如下步骤:
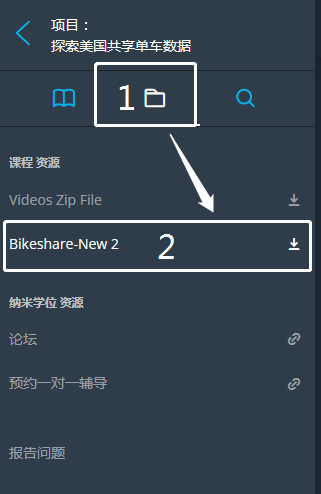
若下载失败,请微信联系我索取。
注意:因为项目文件中使用的是python2,所以在本地环境进行编写时,请按照你的版本对个别代码进行修改,以契合你的版本。完成就可以直接提交,不必再转回python2的语法。
方法准备
在本项目中,你需要完成多个函数的编写,可以按照如下方法提高工作效率:
- 确定第一个函数的功能需求,并构思代码;
- 利用Jupyter Notebook对你构思的代码进行测试;
- 若代码测试功能符合要求,则复制代码至Spyder,完成第一个函数的编写;
- 保存为.py格式的文件,在本地进行功能测试,看是否复合项目要求;
- 若满足要求,则按照步骤1-4对第二个函数进行编写,如此往复,完成整个项目。
大家刚打开项目文件时,先不要被代码量吓到,沉下心来,一步步做,逐一击破,一定没问题哒!
项目流程
项目概述
在此项目中,你将利用 Python 探索与以下三大美国城市的自行车共享系统相关的数据:芝加哥、纽约和华盛顿特区。你将编写代码导入数据,并通过计算描述性统计数据回答有趣的问题。你还将写一个脚本,该脚本会接受原始输入并在终端中创建交互式体验,以展现这些统计信息。
读完项目概述,大概也能了解到项目的要求有哪些了,也就是需要你去完成的任务:
- 需要你编写一个脚本
- 在脚本中,能够读取数据文件
- 能够根据用户输入,完成相关统计计算,并进行回答展示结果
数据集说明
我们提供了三座城市 2017 年上半年的数据。三个数据文件都包含相同的核心列:
- 起始时间 Start Time(例如 2017-01-01 00:07:57)
- 结束时间 End Time(例如 2017-01-01 00:20:53)
- 骑行时长 Trip Duration(例如 776 秒)
- 起始车站 Start Station(例如百老汇街和巴里大道)
- 结束车站 End Station(例如塞奇威克街和北大道)
- 用户类型 User Type(订阅者 Subscriber/Registered 或客户Customer/Casual)
芝加哥和纽约市文件还包含以下两列:
- 性别 Gender
- 出生年份 Birth Year
上述数据集说明中,我们能知道三个数据集中包含有哪些列,列名是什么,这在之后进行函数编写的时候,是一个非常重要的参考。
项目要求
- 请一定要规范注释:
- 关键代码注释,进行解释;
- 函数功能解释文档
- 请保存你初次完成项目的文件作为project_0,之后先备份再修改,这样直到项目审阅成功,你能很明显的对比出自己最开始出现的问题及思考问题的短板。
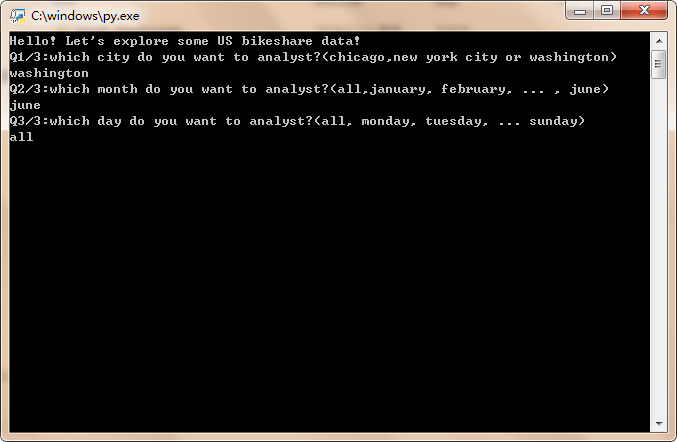
get_filters()函数
代码详解:
1 | def get_filters(): |
关键代码提示:
1 | #获取键盘输入 |
输出示例:
load_data()函数
代码详解:
1 | def load_data(city, month, day): |
关键代码提示:
1 | #pandas读取文档 |
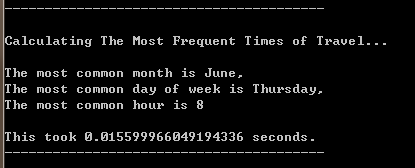
time_stats()函数
代码详解:
1 | def time_stats(df): |
关键代码提示:
1 | #获取众数 |
输出示例:
station_stats()函数
代码详解
1 | def station_stats(df): |
关键代码提示:
1 | #字符串的链接 |
输出示例:
与time_stats()函数类似
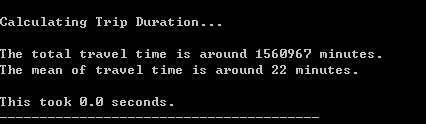
trip_duration_stats()函数
代码详解
1 | def trip_duration_stats(df): |
关键代码提示
1 | #求和 |
输出示例:
 、
、
user_stats()函数
代码详解
1 | def user_stats(df): |
关键代码提示
1 | #pandas 分类同积函数 |
输出示例:
main()函数
main()函数是项目中最重要的函数,是程序的入口。
如果你接手一个项目,想快速了解项目中的代码都实现了哪些功能的话,那就要去查看main()函数,这也就是为什么叫main的原因了。
但是在本项目中,该函数并不需要大家去编写或者修改,完成以上所有函数后,就可以尝试在本地进行测试,然后提交啦~
1 | def main(): |
项目提交
项目提交前,请查看:项目审阅标准,提高你的一次通过率!
总结
至此,我们已经完成了本项目,回想一下,在这个项目中:
- 你都用到了哪些python基础函数?
- 你都用到了哪些pandas中的函数?
- 在你定义的不同函数中,都解决了哪些问题?
- 项目通过之后,再想想你编写的函数是完美的吗?或者说,你有哪些想要进一步完善的?
- 怎样提高用户的体验?比如:get_filters()函数中,用户输入了NewYork,也可以实现正确识别等等
- 怎样保持程序不会报错?比如:华盛顿用户的性别和出生年月。
- 除了项目中的研究内容,你还想继续探究数据中的哪些因素?